Trends and Semantics of Inaugural Addresses
As the new president delivered his inaugural speech just 4 days ago, one additional entry was added to the American Inaugural Address Database. As a diligent data scientist, I could not help to ask this question: across the history, what are the trends and patterns of inaugural speeches?
Of course, asking about trends and patterns is too broad for an analytical task. Therefore, for my analysis I focus on the following questions:
- How has the level of linguistic complexity changed across the history?
- Which presidents had similar semantic patterns in their inaugural addresses?
Answering these questions leads to an NLP exercise that I am sharing in this post. As the input data, I found a download link containing inaugural addresses until 2009, and added to this data set by the 2013 and 2017 addresses that can be downloaded from anywhere.
LINGUISTIC COMPLEXITY
To analyze the linguistic complexity, I computed the following metrics for each inaugural address:
- Number of sentences;
- Average number of words in each sentence;
- Average word length;
- Average constituency parse tree depth;
- Flesch-Kincaid Grade Level.
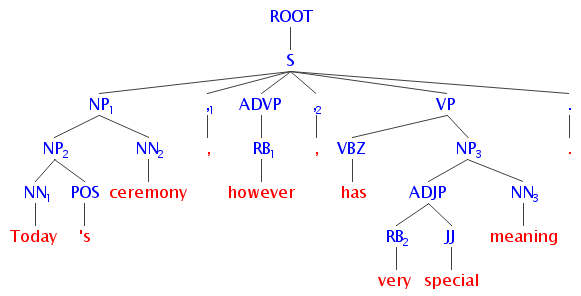
The first three metrics are naive. The constituency parse tree depth describes the syntactic complexity of a sentence. Constituency parse tree describes how different elements in a sentence are syntactically related to each other. Usually the depth of this tree is correlated with a sentence, but not necessarily. The deeper this tree is, the more nested syntactic components are there within the sentence. Take for example, a sample sentence from George Washington’s address has the following parse tree:

While a sample sentence from the new president’s address has the following structure:
Flesch-Kincaid Grade Level aggregates the length of sentences, length of words, and number of syllabus to describe the overall content difficulty of a text passage. The output number, K, means that the text is suitable for a common student in Grade K.
I computed all scores by using python’s NLTK, Stanford CoreNLP and textstat modules. I then produced figures to represent how each metric changed across the years. And here are the results:
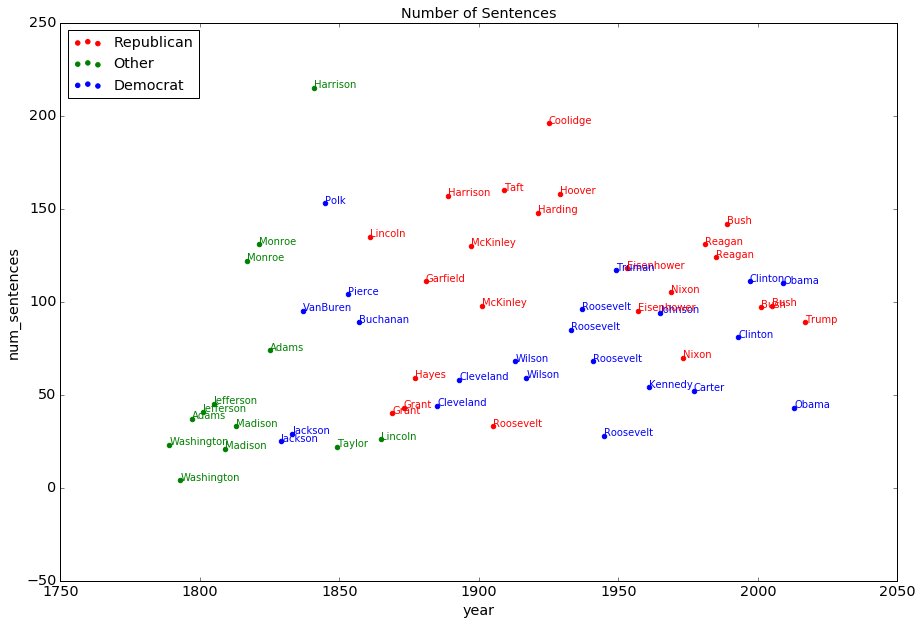

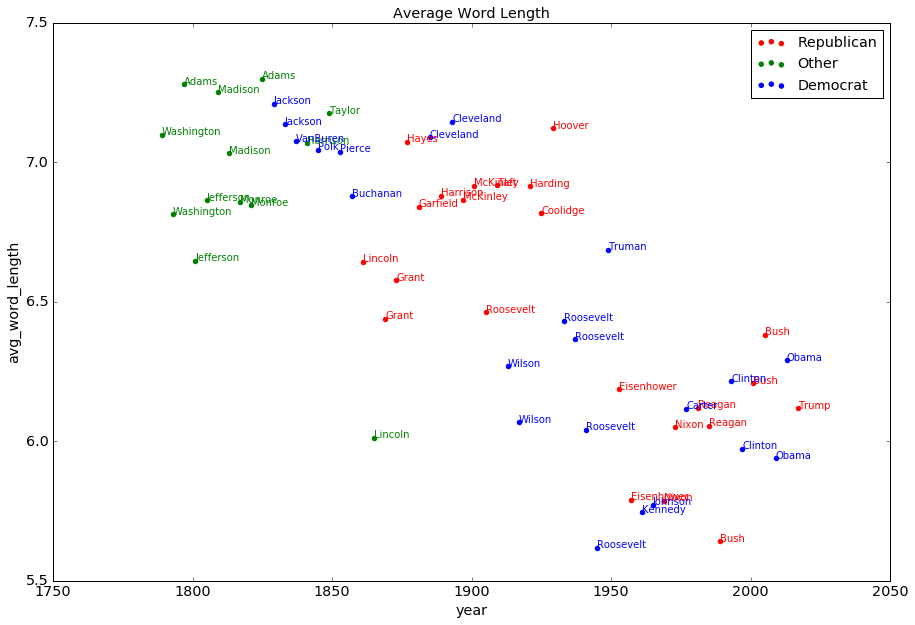
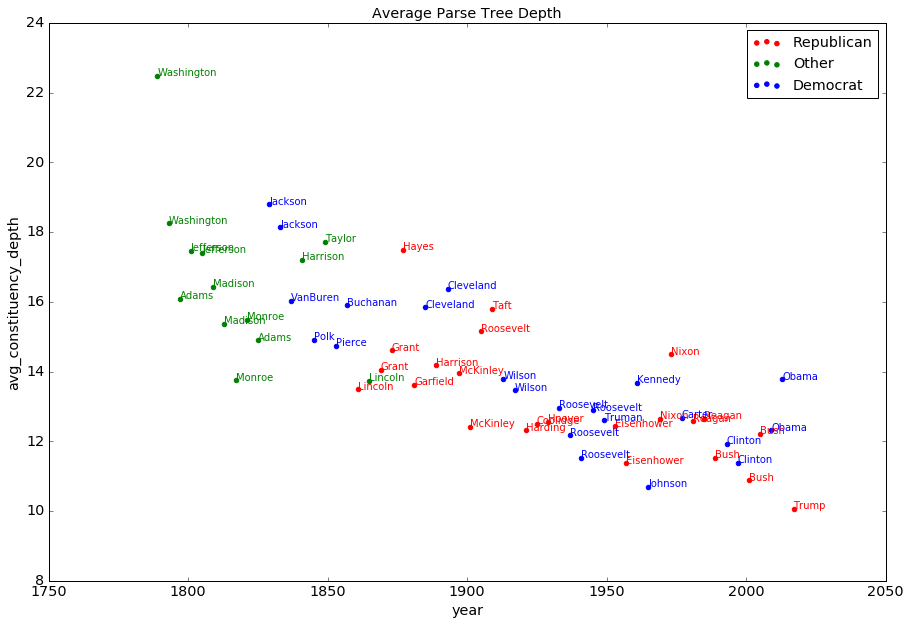
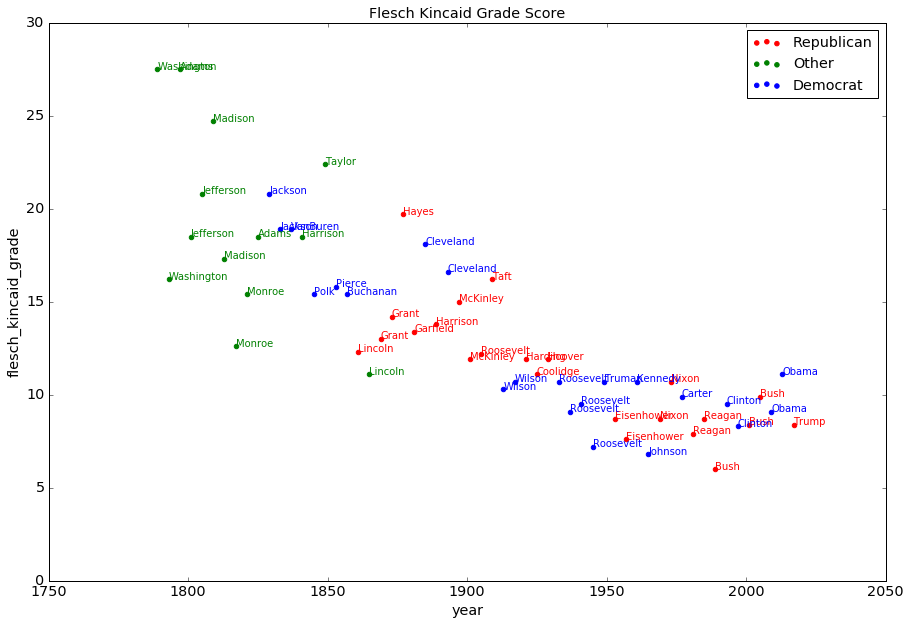
It is interesting that the number of sentences is the only metric that has almost no trend. The length of the address has changed a lot across the history. All other metrics suggest a trend of decay in the linguistic complexity. The new inaugural address sets a record on the simplicity in the syntactic structures, but its sentence shortness is beaten by Johnson, and its average word length is way above the record set by FDR’s final term.
The overall linguistic difficulty, reflected by Flesch Kincaid Grade level, is recorded by Bush(1989), whose address is suitable for the level of Grade 6 students. Our founding fathers have astonishing scores beyond 25 – their inaugural addresses are understandable only by those well educated people. After that, the overall difficulty level kept decreasing until 1970s, after when it slowly increased. The overall difficulty of the new president’s speech is at a similar level as Clinton(1997) and Bush(2001).
SEMANTICS
Besides the linguistic difficulty, I also investigated semantic similarity between all inaugural addresses. Two approaches were taken:
- TF-IDF;
- Latent Dirichlet Analysis(LDA).
Both are quite common models used to compare text similarity. A tricky part is in preprocessing. As both models require identifying inflectional forms of the same word, lemmatizing or stemming is required. Stemming methods are readily available by Python’s NLTK module, but stemming itself is a quite crude way of word processing. Therefore, I used lemmatizing by first applying Python’s Stanford CoreNLP module to perform Part-Of-Speech(POS) tagging, before using NLTK module to lemmatize based on the POS tag.
For both models, I computed the cosine similarity between different inaugural addresses, and applied Local Linear Embedding to visualize. The results are the following:
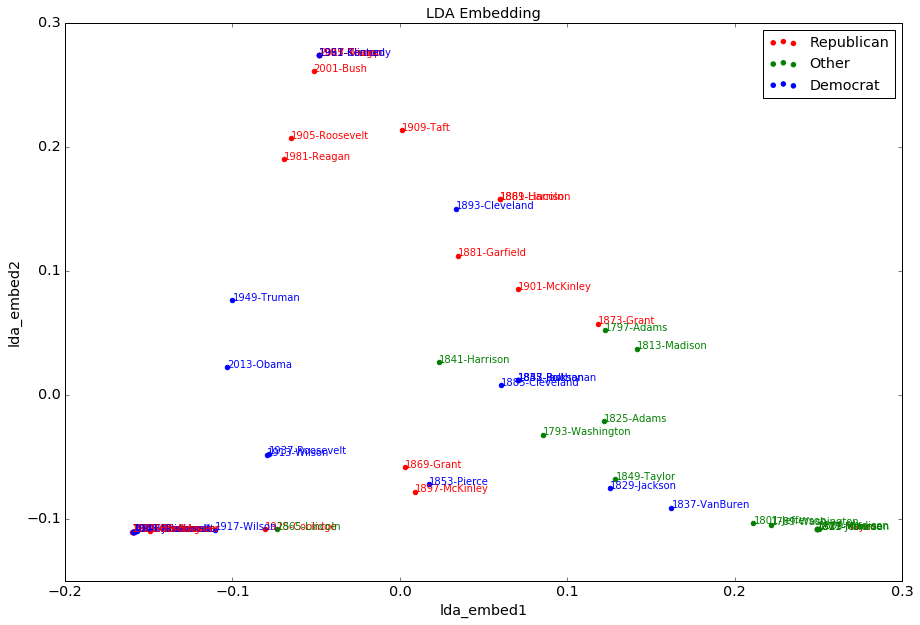

LDA embedding seems not to distinguish a lot among different presidents, perhaps because inaugural speeches are all about the same topics. TF-IDF describes more granular information, by looking at the common words used by different presidents. While presidents in the same era tended to use the same language, different political parties also spoke quite similarly.
Caution, though, that what politicians do are not what they say.
TECHNICAL DETAILS
All technical details are included by my codes.
(c)2017-2026 CHANDLER ZUO ALL RIGHTS PRESERVED